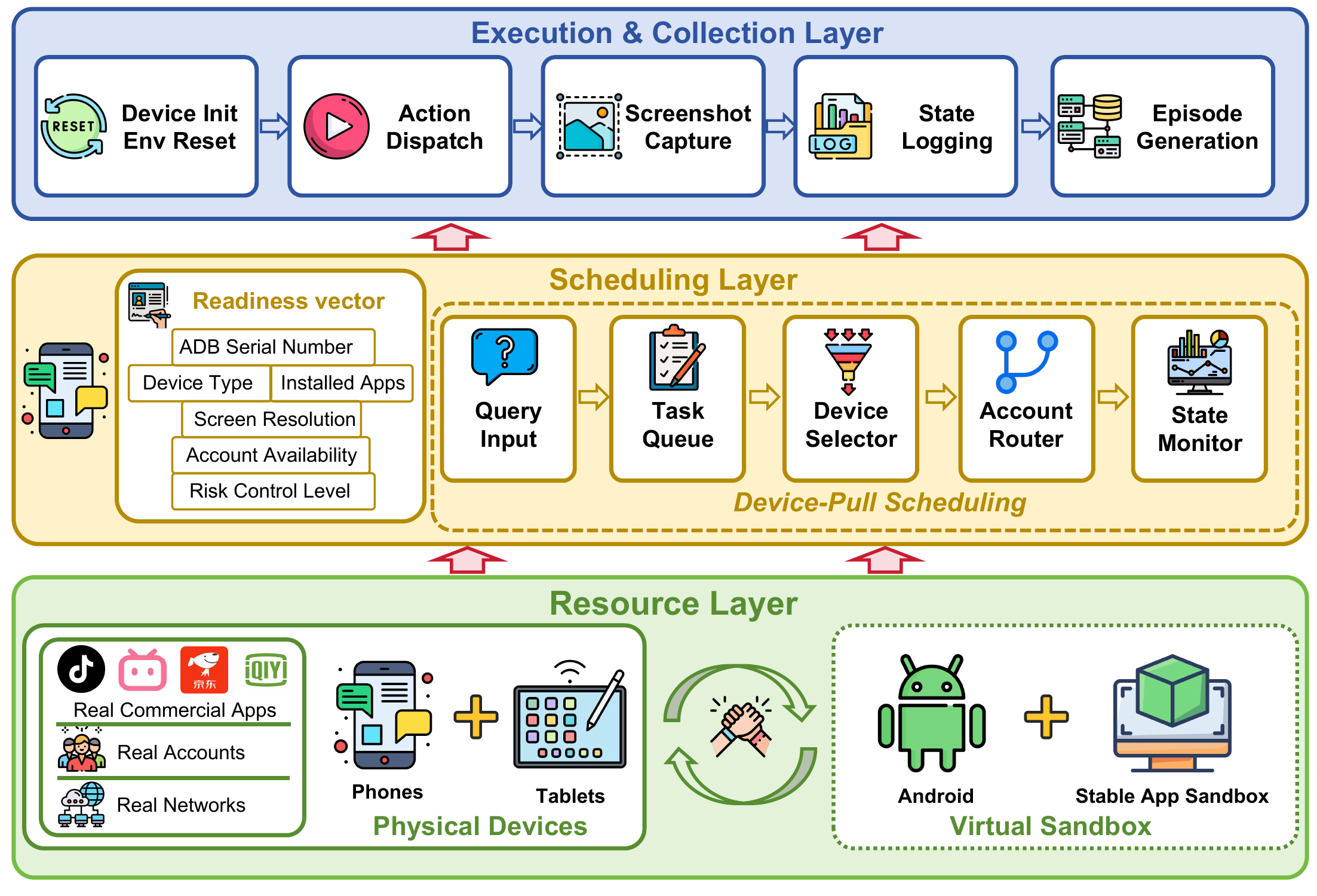
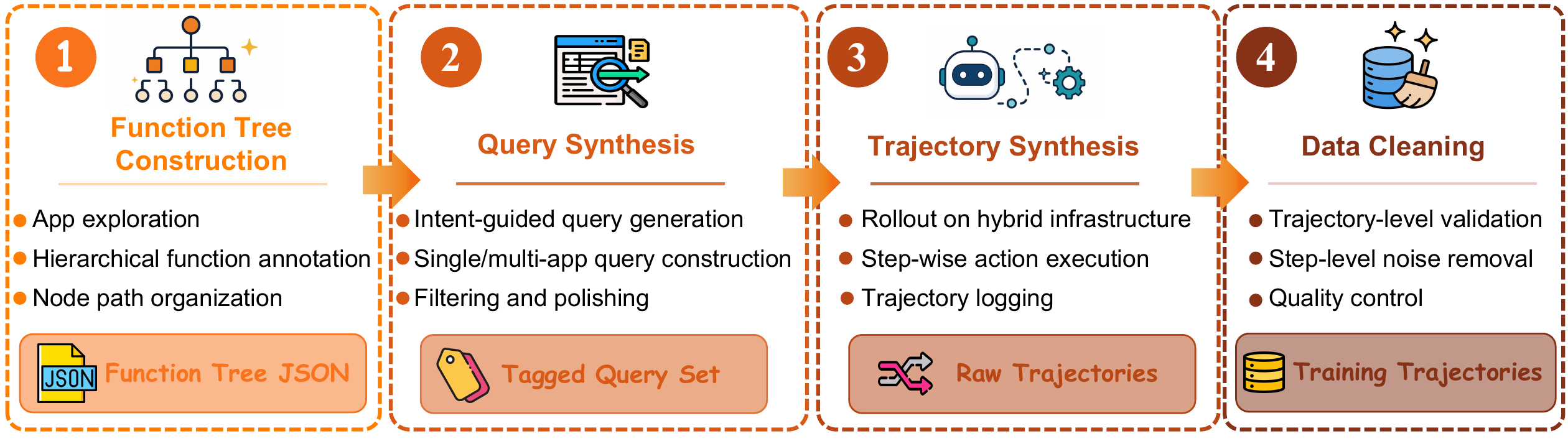
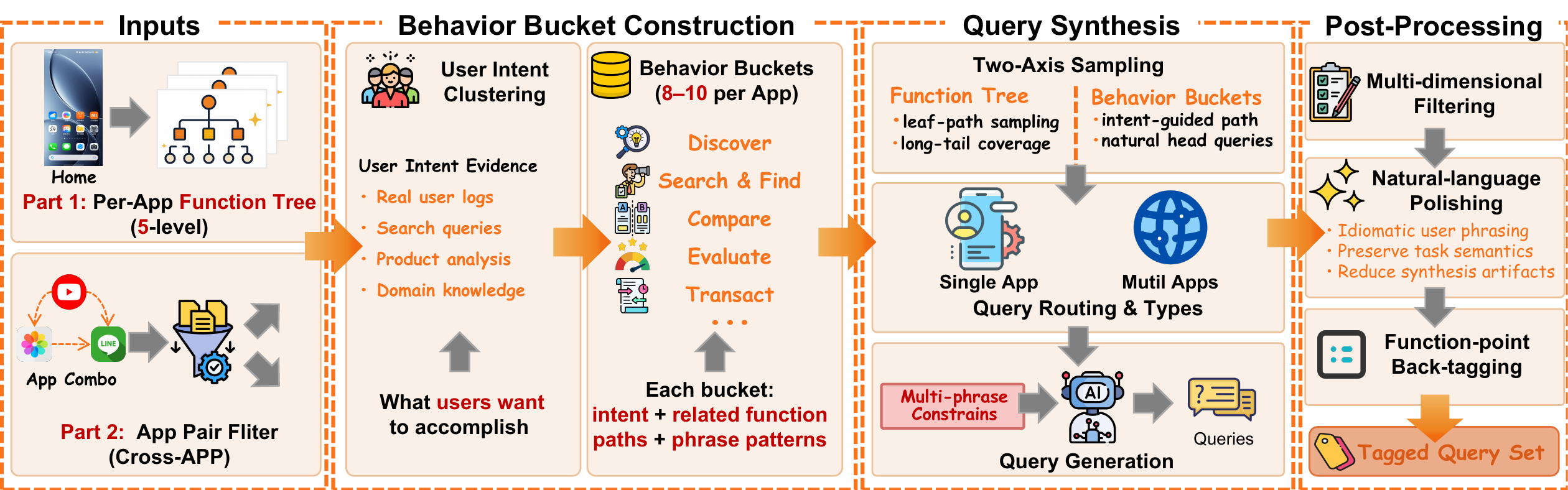
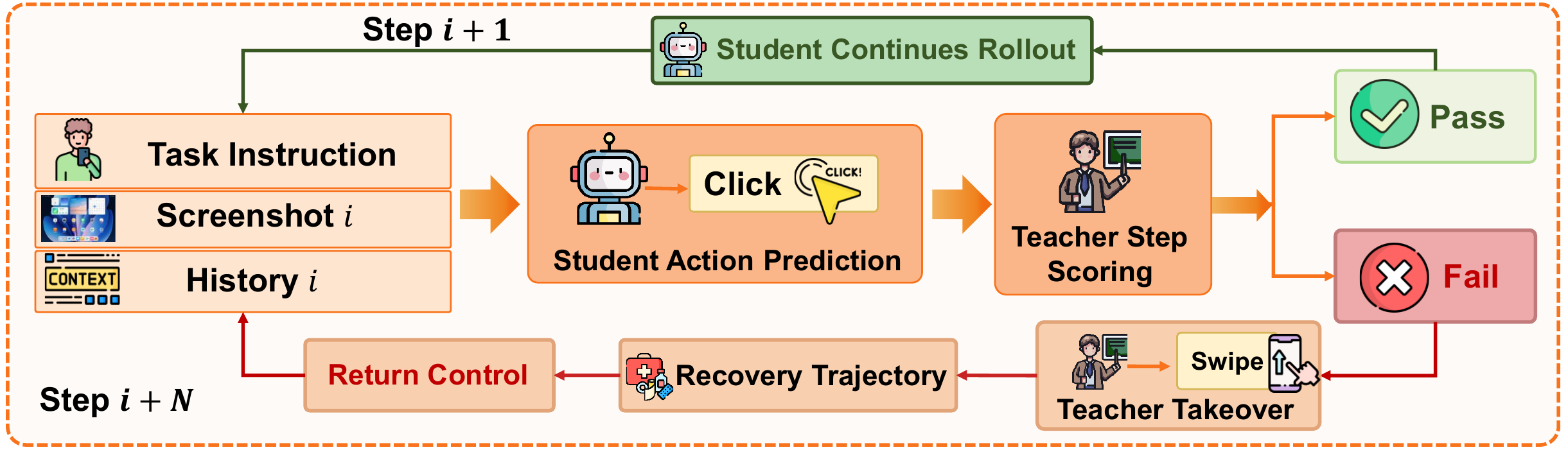
The RealMobile Benchmark
RealMobile is built from real user traffic, hand-crafted for reproducible evaluation, and executed on physical devices against live applications rather than emulators. Each task is scored through fine-grained sub-goals that award partial credit, and most tasks span multiple applications.
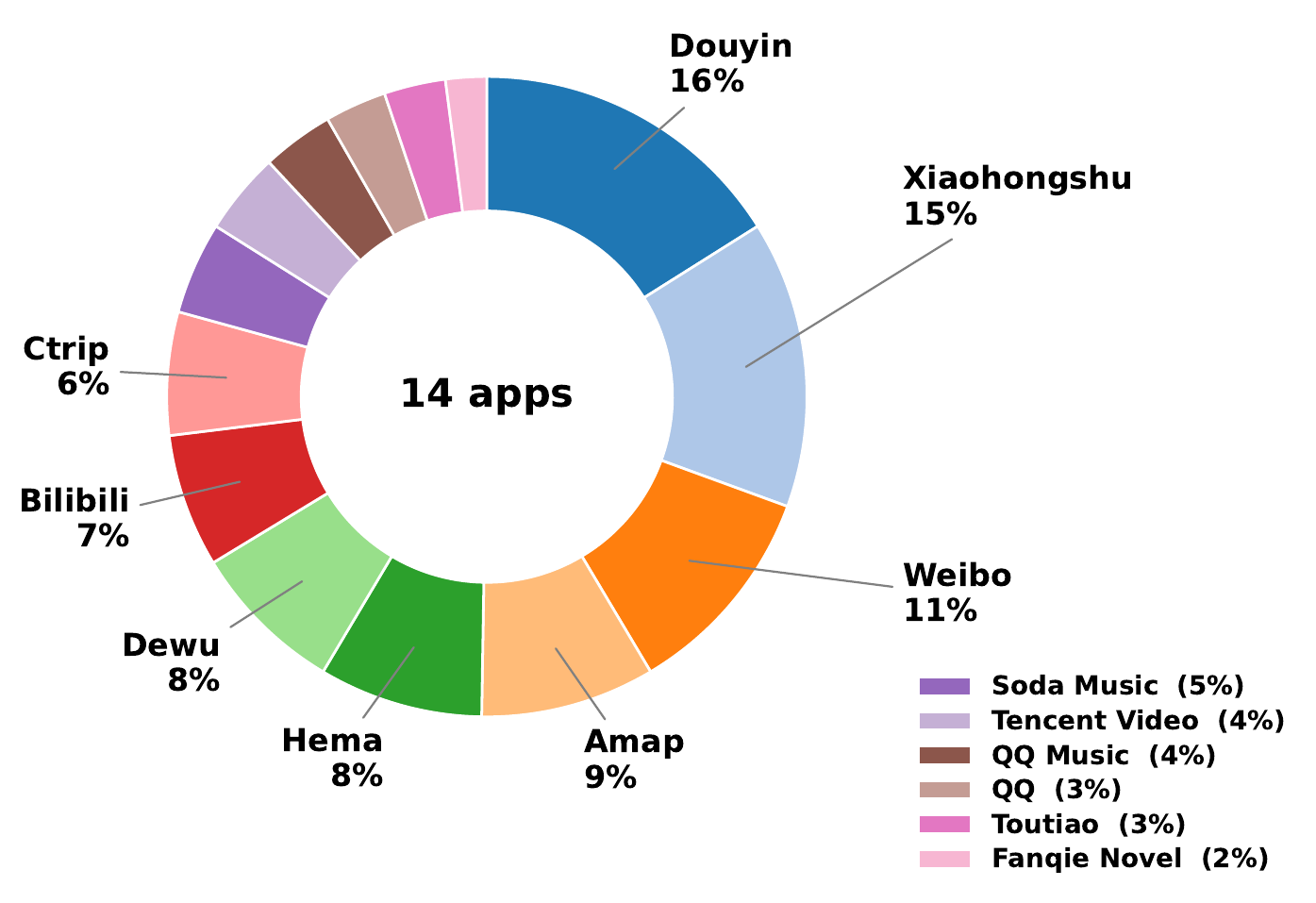
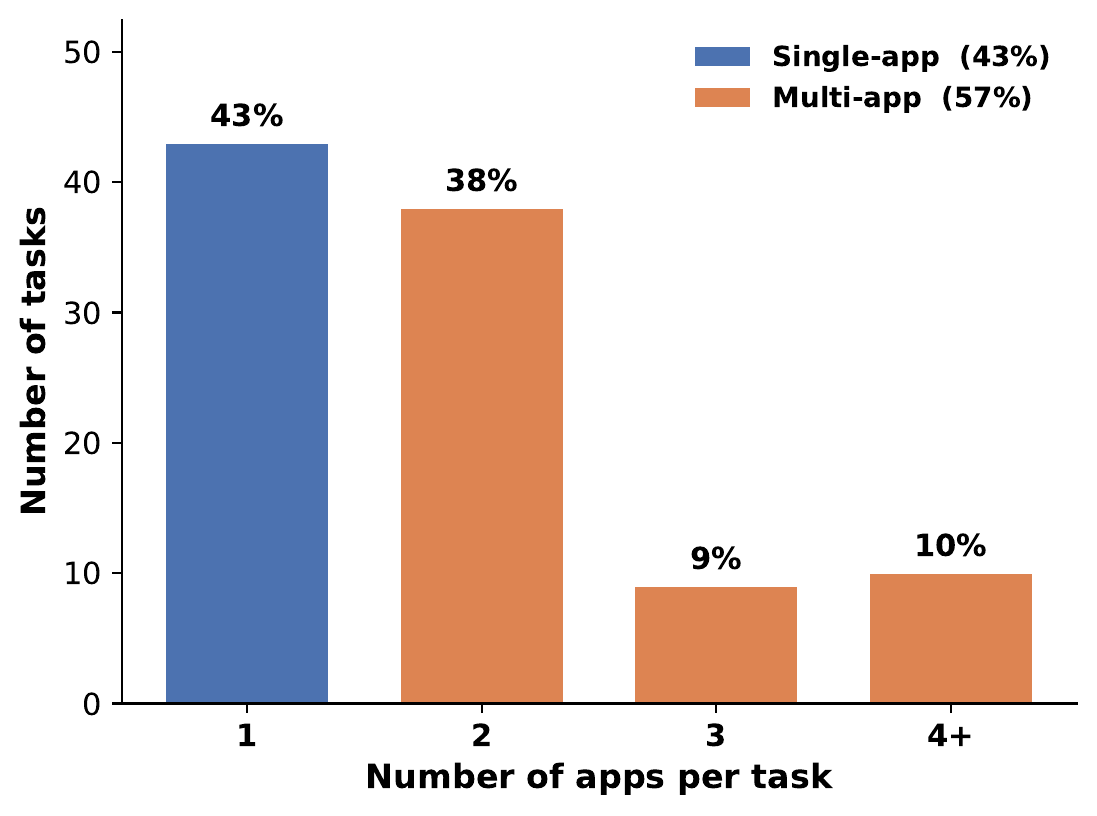
10 tasks
Foundation
Basic GUI operations: clicking, scrolling, inputting, and navigating across interfaces.
16 tasks
Safety & Reflection
Refusing unsafe or irreversible operations, and recognizing infeasible goals to stop or skip.
33 tasks
Memory & Knowledge
Retaining information across steps and applying external knowledge to complete tasks.
41 tasks
Reasoning & Planning
Long-horizon planning, multi-source aggregation, and adaptive decision-making.